OC Processor 101: streamlining knowledge management
An in-depth look at the OC Processor.
By Mihai Gherghe and Misha Kidambi.
In 2006, mathematician and data scientist Clive Humby gave a talk at a conference where he reportedly used the phrase “data is the new oil. Today, over a decade later, the statement holds its ground and is, in fact, more valid than it ever was. Stretching the metaphor of comparing raw data to raw oil is apt—both are not very useful until they are processed. Refining and processing data is a challenge for companies that have to manage and work on extensive knowledge databases. Navigating external information has become a breeze as an array of tools continue to emerge, catering to this ever-growing demand. However, the task of organizing internal information presents a unique set of challenges on its own.
Internal data is often unstructured and is lying scattered across departments and hidden in silos. This is where OntoChem’s offerings, such as the OntoChem Processor, come into the picture to offer solutions.
The OntoChem Processor or OC Processor is a robust and highly customizable solution that has been developed to streamline the process of normalizing, annotating, and extracting knowledge from documents. Simply put, the OC Processor can refine data from documents by preparing, processing, and analyzing it to provide structured data that is rendered accessible and useful.
Starting with the normalization step, the OC Processor reads and recognizes unstructured data from diverse sources, including images, tables, and scanned documents such as PDFs, HTML, XML, MS Office files, and plain text documents. During this stage, the OC Processor detects the structure of a document by analyzing its different elements, such as sections, chapters, authors, in-text referencing to tables and images, etc., and classifies the document accordingly. Concomitantly, the language is analyzed in order to prepare the information for the next step of the processing pipeline: the annotation step.
In the annotation step, the OC Processor maps the scanned information found throughout a document to an existing framework of knowledge. In this way, data such as words and numbers is tagged and assigned a more manageable meaning.
Central to the annotation step of the OC Processor are ontologies. In information science, an ontology is a framework that defines the relationships and categories of entities within a specific domain of knowledge. It provides a structured representation of knowledge, allowing systems to understand, organize, and infer information. This means that an ontology helps organize and connect information in a meaningful way.
The OC Processor can run on OntoChem Ontologies, or users can opt for the flexibility of incorporating their own customized ontologies. In fact, the OC Processor can be used for annotation of confidential documents, together with external documents such as scientific articles, patents, clinical trials, and many others. That way, users can seamlessly compare or connect in-house knowledge with outlying research and discoveries using a pre-defined, universal vocabulary.
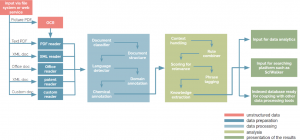
Fig. 1: Overview of the OntoChem Processor pipeline (simplified representation)
Addressing a significant problem in data processing and knowledge extraction, the OC Processor tackles the complex and costly task of extracting facts from over ~91 million full-text publications, 159 million patents, 7 million grants, and many others. While high-quality extraction methods like machine learning exist, those are generalistic and often cannot meet the minimum standards for specialized scientific purposes. Adapting such standard solutions to specific needs requires significant amounts of resources, including in-depth knowledge, development time, and compute resources. Ontochem’s solution lies in the integration of a machine learning module within the OC Processor. The mapped terms from the annotation step are modelled in a frame-based representation, thus allowing for the identification of relationships between concepts. This integration of employing prediction algorithms that combine semantic and machine learning approaches enhances the speed, accuracy, and efficiency of knowledge extraction from internal and external documents.
If you want to learn more about the OC Processor or other OntoChem services, feel free to contact us.